Quick Reference: African Language AI Landscape (2024–2026)
The table below maps the major African language LLM initiatives currently active. Jump to any section below for a full analysis.
| Model / Initiative | Primary Languages | Focus Area | Organization | Open Source? |
|---|---|---|---|---|
| InkubaLM | Swahili, Yoruba, Xhosa, Hausa, Zulu | Efficient small LLM | Lelapa AI (South Africa) | Yes |
| UlizaLlama | Swahili, Hausa, Yoruba, Xhosa, Zulu | Maternal & public health | Jacaranda Health (Kenya) | Yes |
| Lugha-Llama | 16 African languages | Research / QA / retrieval | Princeton AI Lab (USA) | Yes |
| Tiny Aya Earth | 70+ languages (African variant) | On-device / offline AI | Cohere Labs (Canada) | Partial (non-commercial) |
| NLLB-200 | 55 African languages | Machine translation | Meta AI (USA) | Yes |
| Aya 101 / Aya 23 | 101 / 23 languages | Multilingual instruction tuning | Cohere Labs | Yes |
| Nigeria Gov. LLM | Yoruba, Hausa, Igbo, Ibibio, Pidgin | National digital inclusion | Nigerian Government | TBD |
| Masakhane | 50+ African languages | Research infrastructure, datasets | Masakhane Foundation | Yes |
The Numbers That Tell the Story
Africa is home to over 2,000 languages spoken across 54 countries. It is also home to roughly 18% of the world’s population. By 2050, the continent is projected to contain nearly 59% of the world’s working-age workforce.
Yet if you type a query into any mainstream AI assistant in Hausa, Igbo, Sesotho, or Luganda, you will almost certainly get a degraded experience — garbled output, missed nuance, or outright failure.
The gap is stark. English accounts for roughly 50% of all content on the internet. The vast majority of training data for frontier large language models (LLMs) follows that same skewed distribution.
African languages, despite representing roughly a third of the world’s language count, occupy a sliver of that data. The result is a compounding disadvantage: less data means worse models. Worse models mean less adoption. Less adoption means less data generated, and the cycle tightens.
That is beginning to change. Search queries around “Swahili AI model,” “Zulu language AI,” and “Africa multilingual LLM” are growing at over 40% year-on-year. Who is building, why they are building, what the technical and ethical challenges are. What is at stake economically for a continent projected to add $1.5 trillion to its GDP from AI by 2030?
This article is that piece.
Part 1: Why African Languages Are “Low Resource” — And Why That Matters for AI
What “Low-Resource Language” Actually Means
The term “low-resource language” is a technical designation in natural language processing (NLP). A language is classified as low-resource when there is insufficient labeled, clean, digitized data to train effective machine learning models.
The classification is not about how many people speak a language. It is about how much of that language has been converted into the format AI systems can learn from.
This distinction matters enormously. Swahili has over 200 million speakers. It is the official language of Kenya, Tanzania, Uganda, and the African Union. Yet it is dramatically underrepresented in AI training data compared to its actual use. The reason is not that Swahili speakers are rare — it is that most of Swahili’s living use happens in spoken conversation, in handwritten documents, in community spaces that have never been digitized.

Comparison of the English training data (roughly 50%) to the critically underrepresented data for all African languages combined.
Why African Languages Face This Problem More Than Others
For African languages, data scarcity has multiple compounding causes.
Colonialism displaced indigenous languages from formal education, government, and publishing for generations. This structural marginalization meant far less was ever written down in these languages to begin with. Oral tradition remains the primary mode of knowledge transmission in many communities. And even where text exists, it is often behind institutional paywalls or scattered across archives that have never been digitized.
The academic paper “The State of Large Language Models for African Languages” (2025) found that Africa’s languages “face significant challenges such as a lack of data, limited computational resources, insufficient NLP tools, and the absence of standardized benchmarks.” Of the roughly 37 writing systems historically used by African communities, 14 are no longer in active use — a cultural loss that also means no digital corpus exists for those languages.
The consequences are not merely inconvenient. As the Carnegie Endowment for International Peace observed in a 2024 analysis: many multilingual models claim to support African languages but are not fit for purpose for the communities they claim to serve.
Incorrect translations can have life-changing consequences depending on how they are used. In healthcare, a mistranslation of a dosage instruction is not an annoyance — it is a patient safety risk. In legal and civic contexts, AI systems that fail in local languages entrench rather than reduce inequality.
The Digital Extinction Risk: AI and the Fate of Endangered African Languages
This is a dimension that deserves its own discussion. Of Africa’s 2,000+ languages, linguists estimate hundreds are endangered — spoken by shrinking communities, with no written standard and no digital presence. The 14 historical African writing systems that are no longer in active use represent a real precedent for what can be lost.
For these endangered languages, the stakes of the African LLM movement extend beyond convenience or economic inclusion. They touch on cultural survival.
When a language disappears from the digital sphere. When it cannot be used to communicate with AI systems. Cannot generate searchable content, cannot be recognized by voice assistants — it loses a critical pathway to transmission with younger generations.
Children growing up with smartphones and internet access will gravitate toward languages their devices understand. A Yoruba-speaking teenager in Lagos who finds that English gets far better AI responses than Yoruba receives a daily, subtle signal about which language matters.
AI, then, cuts both ways. A poorly built or absent African-language AI accelerates digital extinction. A well-built one can reverse the signal: it tells communities that their language is legitimate in the digital world, that it can be used to access services, education, commerce, and information.
Masakhane’s BibleTTS project — which created text-to-speech datasets for African languages — is one example of this preservation-by-digitization approach. The goal is not just to make AI work in Yoruba. It is to ensure Yoruba survives into the digital era.
The World Economic Forum’s analysis on Africa’s technology opportunity explicitly identifies language barriers as a structural obstacle to digital inclusion. It notes that approximately 2,000 languages are spoken in Africa and that most digital content is in none of them. AI that bridges that gap does not just serve the economy. It serves the culture.
Part 2: The Builders — A Field Guide to Who Is Building African Language LLMs
Lelapa AI — Africa’s First Homegrown Multilingual LLM
The most symbolically significant milestone in African-language AI came in August 2024. That is when Johannesburg-based Lelapa AI launched InkubaLM — widely described as Africa’s first multilingual AI large language model built on the continent, for the continent. The model covers Swahili, Yoruba, IsiXhosa, Hausa, and isiZulu.
The name is deliberate: “Inkuba” is the isiZulu word for “dung beetle” — an insect celebrated for doing difficult work with remarkable efficiency and limited resources. InkubaLM-0.4B has just 400 million parameters, trained from scratch on 1.9 billion tokens across its five target African languages (plus English and French for multilingual transfer), totaling 2.4 billion tokens. For context, GPT-4 is estimated to have over a trillion parameters.
InkubaLM is tiny by the standards of frontier AI. That is precisely the point: a smaller model is cheaper to run, faster to deploy, and more accessible to developers working with limited compute budgets in African markets.
Inkuba-Instruct
The instruction dataset, Inkuba-Instruct, covers five NLP tasks: machine translation, sentiment analysis, named entity recognition (NER), parts-of-speech tagging, and question answering. These are the building blocks for real-world applications in commerce, healthcare, education, and government services. Lelapa also released two open-access datasets — Inkuba-Mono and Inkuba-Instruct — as research infrastructure for the broader African NLP community.
Pelonomi Moiloa, CEO of Lelapa AI, has been direct about the stakes: “No one should have to assimilate to a culture outside of their own in order to access cutting edge technology.” Co-founder Vukosi Marivate, also an associate professor of computer science at the University of Pretoria, has raised a pointed warning: “A lot of people are working on LLMs now because of the prestige, that’s where the money is, but we need to make sure that our languages are actually being taken care of.”
That warning — about prestige without stewardship — points to a real risk. The field is drawing attention, and not all of it is equally careful or community-centered.
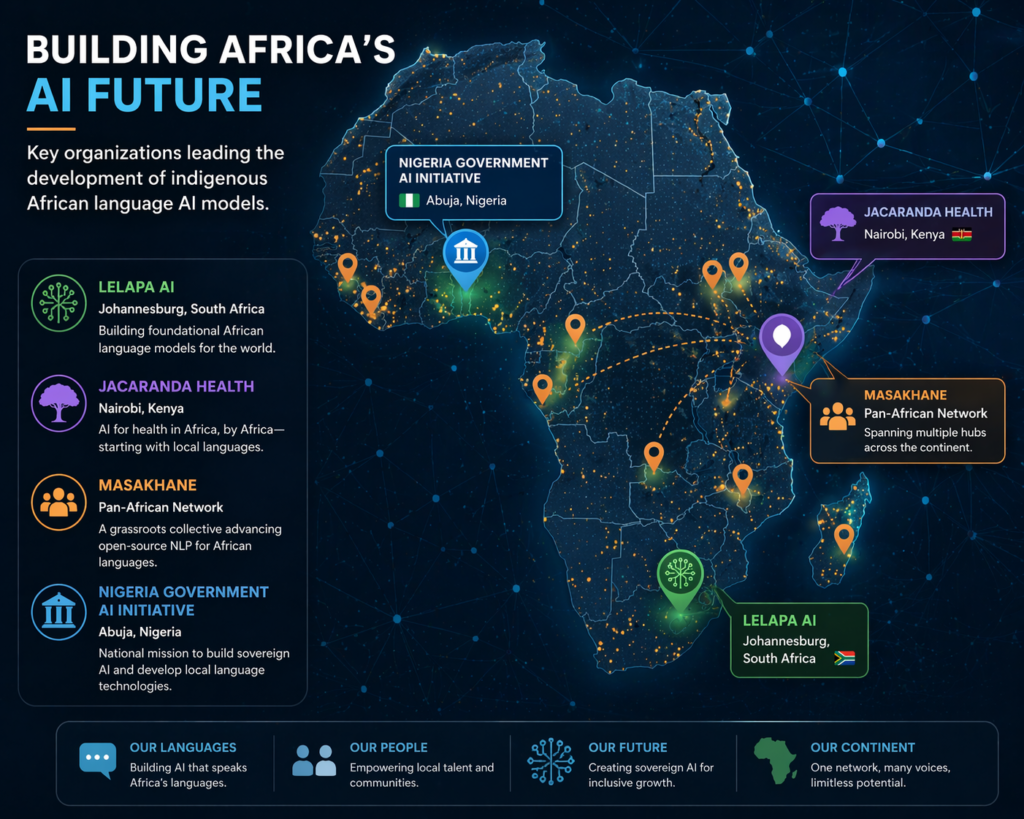
Key locations of organizations leading the development of indigenous African language AI models.
Masakhane — The Grassroots Research Engine
If Lelapa AI is building the products, Masakhane is building the foundation beneath them. Founded as a grassroots research collective, Masakhane’s mission — encapsulated in its name, which roughly translates to “We build together” in isiZulu — is to strengthen NLP research in African languages for Africans, by Africans.
Masakhane has grown into a network of over 2,000 researchers actively publishing research across machine translation, named entity recognition, speech processing, and language modeling.
Large collaborative projects have emerged from its network: MasakhaNER (with 61 co-authors), quality assessments of multilingual datasets (51 co-authors), and corpora-building initiatives for specific language communities. The KenCorpus project — a community-driven effort to create large Kenyan language datasets — has been downloaded over 500,000 times.
The organization’s HuggingFace presence — which includes the AfroBench dataset for benchmarking LLMs across African languages — has become essential infrastructure for the entire field. Without the benchmarks Masakhane has helped create, it would be nearly impossible to rigorously evaluate whether any given African-language model is actually performing well or just appearing to.
The AfricaNLP workshop, anchored by Masakhane, is the annual convening point for this community. Its 2024 edition, hosted at ICLR in Vienna, was themed “Adaptation of Generative AI for African Languages.” The 2025 edition, co-located with ACL, continued that trajectory — bringing together researchers from across the globe who are building, evaluating, and deploying AI systems for African language communities.
Jacaranda Health — Swahili, Hausa, Yoruba, Xhosa, and Zulu in Maternal Care
One of the most compelling applied cases for African-language LLMs comes from healthcare. Nairobi-based Jacaranda Health built and open-sourced UlizaLlama — an LLM tuned for maternal health information delivery in five African languages: Swahili, Hausa, Yoruba, Xhosa, and Zulu.
The technical approach was rigorous. The team pre-trained Meta’s Llama3 for each individual language, merged those pre-trained models, and fine-tuned the combined model. They evaluated quality using 2,500 questions drawn from their real patient query database, measuring exact matches, semantic similarity, correspondence, and fluency. The UlizaMama models outperformed base models across every metric.
The deployment context is critical. Jacaranda’s platform, PROMPTS, delivers AI-driven health support to new and expectant mothers in peri-urban Nairobi. Its expansion into Hausa, Yoruba, Xhosa, and Zulu reflects ambitions in Nigeria and South Africa. By open-sourcing the models, Jacaranda is making the case that African-language health AI is a public good.
The vision extends beyond maternal health: the same multilingual architecture could assist farmers with crop advice in Yoruba, help researchers translate scientific papers into Hausa, or help social services deliver information in Xhosa. All five language models — including a combined multilingual model — are available on HuggingFace.
Princeton’s Lugha-Llama — Research-Grade Performance Across 16 Languages
In 2025, researchers at Princeton’s Laboratory for Artificial Intelligence Research released Lugha-Llama — Lugha being Kiswahili for “language.” The project released three African-centric models built by continually pre-training Meta’s Llama-3.1-8B on the WURA corpus, which covers sixteen African languages and four high-resource languages commonly spoken on the continent.
Lugha-Llama achieved state-of-the-art performance among open-source models on IrokoBench — the field’s most challenging African-language evaluation benchmark — and AfriQA, a cross-lingual open-retrieval question answering dataset.
The key finding: integrating African language pre-training data with high-quality English documents substantially improves downstream performance. You do not need to strip out English to build strong African-language models. Cross-language transfer is a tool, not a threat.
Nigeria’s Government Initiative — AI Sovereignty as National Policy
In April 2024, Nigeria’s Digital Economy Minister Bosun Tijani announced a government-led initiative to develop a multilingual LLM covering five languages — Yoruba, Hausa, Igbo, Ibibio, and Nigerian Pidgin — plus accented English.
The plan involves partnering with Nigerian AI startups and mobilizing over 7,000 fellows from Nigeria’s national tech talent program to collect and clean training data from fluent native speakers.
This is the first time a major African government has made African-language LLM development an explicit state priority. It reflects a growing understanding that AI sovereignty — the ability of a nation to build and control its own AI systems in its own languages — is a dimension of economic and political sovereignty, not just research.
Cohere Labs — Aya, Aya 23, and Tiny Aya: A Global Multilingual Effort Rooted in Africa
Canadian AI company Cohere’s research nonprofit, Cohere Labs, has pursued one of the most ambitious multilingual AI programs globally through its Aya initiative. The name comes from the Twi language of Ghana, symbolizing endurance and resourcefulness.
Aya-101 (February 2024)
was an open-source, instruction-fine-tuned model covering 101 languages, built through a global collaborative effort with over 3,000 researchers from 119 countries. The Aya dataset comprises over 200,000 high-quality human annotations in 65 languages, combined with an Aya Collection of 513 million instances across 114 languages — the largest human-curated multilingual instruction fine-tuning dataset ever assembled.
Aya 23 (mid-2024)
shifted philosophy: rather than breadth across 101 languages, it pursued depth across 23 — achieving up to 14% improvement on discriminative tasks, up to 20% on generative tasks, and a 6.6x increase in multilingual mathematical reasoning compared to Aya 101.
Tiny Aya
(February 2026) is the most consequential for African deployment. A 3.35 billion parameter small language model supporting 70+ languages, it is explicitly designed to run locally on devices — including phones — without cloud dependency. The Africa-specific Tiny Aya Earth variant achieved 39.2% accuracy on the GlobalMGSM African-language math benchmark, compared to 17.6% for Gemma 3-4B and just 6.25% for Qwen3-4B.
The ability to run these models on low-end hardware without internet is not a minor engineering detail. In Africa, where large cloud data centers are concentrated primarily in South Africa, Egypt, Nigeria, and Kenya, on-device AI is a practical necessity for reaching the majority of the continent’s population.
Meta’s NLLB-200 — The Foundation Layer for African-Language Translation
Meta’s No Language Left Behind (NLLB) project, launched in 2022, remains the most significant contribution to African language AI from a major tech company. The NLLB-200 model delivers high-quality translations directly between 200 languages — including 55 African languages. Before NLLB, fewer than 25 African languages were supported by mainstream translation tools.
The accuracy gains are substantial: NLLB-200 achieved BLEU scores averaging 44% higher than previous state-of-the-art models, and for some African languages the improvement exceeded 70%.
Meta open-sourced the model, offered up to $200,000 in grants to nonprofits deploying it for social good, and partnered with the Wikimedia Foundation — so African-language Wikipedia editors now use NLLB to translate and expand articles in languages like Luganda and Swahili.
NLLB is primarily a translation model rather than a generative LLM. But it seeded a generation of downstream applications and served as training-data infrastructure for subsequent models.
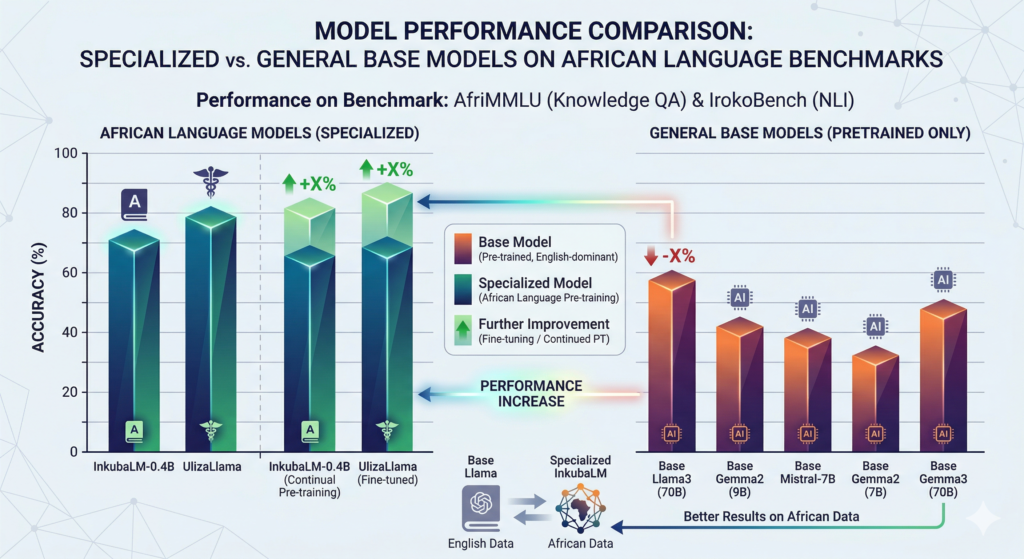
Accuracy and performance of specialized African language LLMs versus general-purpose base models on African language benchmarks.
Part 3: The Technical Challenges of Building African Language AI
The Data Scarcity Problem
Every builder in this space confronts the same fundamental problem: there is not enough clean, labeled, digitized African-language text to train state-of-the-art models. The approaches to solving this diverge.
Data archaeology involves mining existing sources — religious texts (which exist in many African languages thanks to missionary translation efforts), parliamentary records, newspaper archives, Wikipedia articles, and social media.
The risk is well-documented: over-reliance on religious texts produces models that handle biblical vocabulary well but struggle with everyday speech, medical terminology, or technical language. The Yankari Yoruba dataset (presented at AfricaNLP 2025) deliberately drew from 13 diverse sources — news outlets, blogs, and educational materials — to avoid exactly this trap.
Human annotation and community participation is Masakhane’s signature approach. Rather than scraping existing text, Masakhane has developed participatory methodologies that treat language communities as co-creators, not data sources.
Synthetic data generation is the newest frontier. Cohere’s Tiny Aya used a “Fusion-of-N” pipeline: prompts were sent to a team of teacher models (including Command A, Gemma3-27B, and DeepSeek-V3), and a judge model extracted and aggregated the strongest components. This approach generates high-quality training signal for low-resource languages without requiring as much human annotation — a promising path to scale.
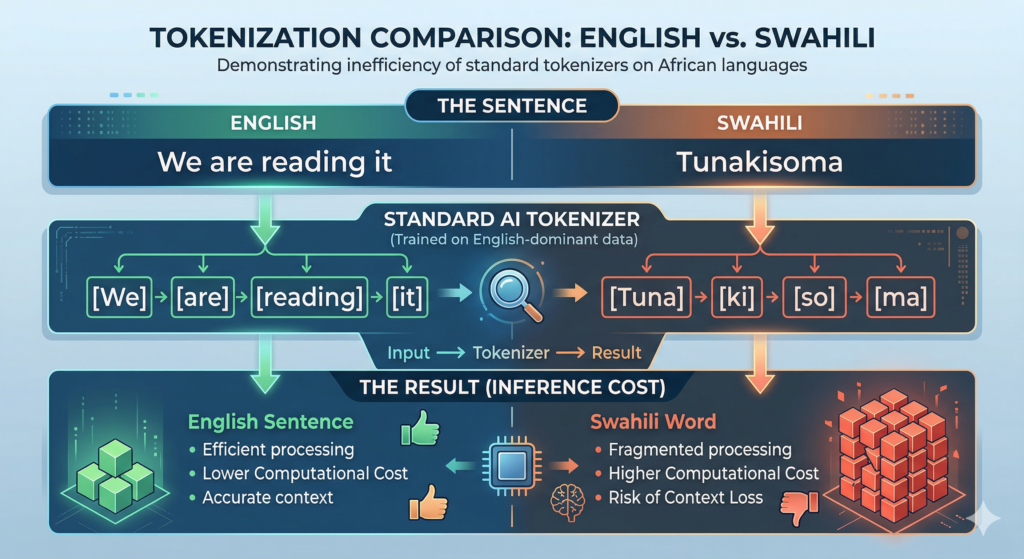
The Tokenization Problem: Why African AI Costs More to Run
Tokenization is the process by which LLMs break text into tokens — roughly word-pieces — before processing. Most tokenizers are trained on English-dominant data and handle African languages inefficiently.
The consequence is direct and economically significant. A sentence in Swahili or Zulu may tokenize into far more tokens than the equivalent English sentence, even when expressing the same concept.
This means African-language inference costs more compute, the model’s effective context window shrinks, and performance degrades. For developers and organizations operating on constrained budgets in African markets, this efficiency gap is a real barrier to deployment.
InkubaLM addressed this by training its tokenizer from scratch, producing a vocabulary of 61,788 tokens optimized for its five target languages. Tiny Aya used a 262,000-token vocabulary explicitly designed for equitable language representation. Both are deliberate rejections of the assumption that a tokenizer built for English will generalize adequately.
The Benchmark Problem: How Do You Know If an African-Language Model Actually Works?
You cannot improve what you cannot measure. For years, African-language NLP lacked rigorous, standardized benchmarks. That absence made it easy for models to claim African-language support without being held to account.
IrokoBench (2024) changed that. It provides multi-choice knowledge QA (AfriMMLU) and natural language inference (AfriXNLI) across multiple African languages. AfroBench, maintained by Masakhane on HuggingFace, aggregates multiple evaluation frameworks. Lugha-Llama, InkubaLM, and Tiny Aya Earth have all been evaluated against these benchmarks — enabling direct comparison.
The existence of shared benchmarks is not a minor technical detail. It is what allows a global research community to distinguish real progress from marketing claims. The rapid maturation of the AfricaNLP evaluation ecosystem between 2022 and 2025 is one of the most important developments in the field.
Part 4: The Ethical Minefield — Consent, Ownership, and Cultural Risk

Ancient African oral traditions and modern digital language data collection for AI
Who Owns an African Language?
“There are questions of who owns the language and who benefits,” said Michael Michie, co-founder of Everse Technology Africa, in a Reuters Foundation investigation. “There needs to be guidelines to prevent exploitation and ensure the development of these LLMs benefits the people they are meant to serve.”
The concern is not hypothetical. In many African communities, oral tradition is dominant — meaning language data cannot be scraped from the web. It must be collected from people. That collection raises questions about consent, compensation, and control that current AI regulation in most African countries has not addressed.
As Michie noted: “There are currently no regulations or laws in African countries that address issues related to consent, privacy and compensation to communities when collecting data to train AI tools.”
This issue is distinct from Western data privacy discourse, which focuses on individuals. The African context introduces a community dimension: certain knowledge, certain oral traditions, certain dialects may be considered collective property. A community may not want its language used to train commercial AI systems, regardless of individual consent.
The Open-Source Dilemma
Open-source licensing is widely advocated as a democratizing force for African-language AI. But Lelapa AI co-founder Vukosi Marivate has raised a pointed counterargument: “If everything is open source, it may be harder to properly reimburse and acknowledge the original contributors to these language models.”
The tension is genuine. Open access accelerates research and prevents large foreign companies from monopolizing African languages. But pure open-source licensing can mean the communities who contributed language data receive nothing when a commercial entity profits from the resulting model.
Masakhane’s position navigates this carefully. Its openness principle is not open-for-all — it is open-for-the-communities-it-serves. The framing rejects both complete proprietarization and unlimited extraction.
The Accuracy-Consequence Gap in Healthcare and Civic AI
The Carnegie Endowment analysis pointed to a concrete illustration of why accuracy in African-language AI is a safety issue, not just a performance metric. AI content moderation systems have already failed in African languages, allowing harmful content to spread in languages the systems could not properly understand. The inverse risk is equally real: systems that over-censor because they cannot parse African-language nuance.
In healthcare — where Jacaranda Health’s UlizaMama and similar deployments are pushing African-language LLMs into real clinical use — the stakes are higher still. A mistranslated maternal health instruction is not a benchmark failure. It is a potential harm to a patient.
Part 5: The Economic Stakes — Why This Is a $1.5 Trillion Question
The GDP Opportunity
AI and emerging technologies are projected to contribute approximately $1.5 trillion to Africa’s GDP by 2030, according to the World Economic Forum. The African AI market itself is projected to reach $16.5 billion by 2030, growing at a compound annual growth rate of 27.42%.
But those numbers depend on adoption. And adoption depends, in large part, on whether AI systems can communicate in the languages of the people using them. The McKinsey 2025 analysis of Africa’s generative AI opportunity identified AI-driven translation and localization for underrepresented African languages as one of the key early use cases already generating returns across agriculture, healthcare, retail, and education.
The Digital Inclusion Argument
As of 2023, only about 37% of Africa’s population had internet access. Mobile connectivity is the primary access vector, with mobile broadband coverage reaching 85% of sub-Saharan Africa — but actual mobile internet penetration at just 25%. Among the barriers: smartphones can cost up to 95% of the monthly income of the poorest 20%. And language. Most digital content is in none of Africa’s languages.
An AI that cannot function in someone’s native language is not merely inconvenient. It is exclusionary. If AI becomes the primary interface for accessing government services, healthcare, financial products, educational content, and commerce, then African-language LLMs are not a niche research concern. They are infrastructure for economic participation.
The African Union’s declaration of AI as a strategic priority in May 2025 acknowledged the concentration problem directly: “Over 83% of AI startup funding in Q1 2025 went to Kenya, Nigeria, South Africa, and Egypt. AI should help narrow the digital divide, not widen it.” Africa currently houses only 3% of the global AI talent pool, and brain drain continues to move that talent toward high-resource environments.
Education and the Youngest Population on Earth
Africa is on track to represent over one-third of the global workforce by 2050. The continent has the world’s youngest population. An education system that cannot leverage AI in the languages students speak natively trains students to operate in someone else’s digital economy — not their own.
AI-powered personalized learning in Swahili, Hausa, or Amharic has the potential to narrow skills gaps, improve outcomes in low-connectivity areas, and connect curricula to cultural contexts that give students genuine ownership. Kenya is already piloting AI-powered personalized learning pathways for students. The eLearning Africa 2025 conference in Nairobi identified indigenous knowledge systems and AI readiness as central to the continent’s educational strategy.

Maternal health worker in Nairobi uses a specialized AI-powered tablet interface to deliver healthcare guidance in Swahili to an expectant mother.
Part 6: The Concentration Problem — Who Is Being Left Out
The field is growing. But it is not growing evenly. Swahili, Hausa, Yoruba, Zulu, and Xhosa are attracting the most research attention — for understandable reasons given their speaker populations — but this means hundreds of other languages remain almost entirely unaddressed by modern AI.
Research on Ethiopian languages (Amharic, Tigrinya), Kinyarwanda, Luganda, Lingala, and the dozens of smaller languages across West, Central, and East Africa is far sparser. The five languages targeted by InkubaLM and the five in UlizaMama are not the five least-resourced African languages. They are simply among the most tractable starting points.
This is not a criticism of the pioneers. You must start somewhere. But it is a caution against declaring the problem solved when a handful of high-visibility languages receive attention while the long tail of Africa’s linguistic diversity remains neglected. Even excellent progress on the leading 10–20 African languages addresses only a fraction of the continent’s 2,000-language reality.
Part 7: What Comes Next for African Language AI

A user in rural Senegal confidently operates an advanced language translation application on their smartphone.
On-device models will matter more than frontier scale.
Tiny Aya’s ability to run on phones without internet is a design philosophy, not just a product feature. In a continent where cloud infrastructure is concentrated in a few cities, the ability to run capable AI locally is a genuine differentiator. Expect more small-but-capable African-language models optimized for mobile deployment.
Community-centered data collection will become standard practice.
The ethical shortcomings of scraping and synthetic generation for low-resource languages are well understood by African NLP practitioners. Projects that compensate communities and give them governance over how their language data is used will produce better data and build greater trust.
Benchmarks will proliferate and mature
IrokoBench and AfroBench have given the field evaluation infrastructure it lacked three years ago. As more models submit to these benchmarks, the community will develop a clearer picture of where real progress is being made — and where performance claims are marketing, not science.
Government engagement will intensify
Nigeria’s government-led multilingual LLM initiative is unlikely to be the last of its kind. AI sovereignty — the ability to build, own, and govern AI systems in local languages — is increasingly understood as a dimension of economic and political sovereignty. More African governments will fund indigenous-language AI programs.
Speech AI will unlock the next billion
The focus to date has been largely on text-based LLMs. But for many African languages, and for the hundreds of millions of people on the continent who are not literate in a formal script, speech recognition and text-to-speech in local languages may matter more than text generation. Projects like BibleTTS and ASR research presented at AfricaNLP 2025 are building the foundation for voice-native African AI.
The Stakes of Getting This Right
The race to build African-language LLMs is, at its core, a question about who the AI revolution is for.
If the answer is “speakers of English, Mandarin, Spanish, and a handful of other high-resource languages,” then the 1.4 billion people on the African continent are observers of someone else’s transformation — not participants in their own. Their languages quietly fade from the digital world. Their children receive the daily signal that their mother tongue does not compute.
The builders profiled here — Lelapa AI, Masakhane, Jacaranda Health, Princeton’s AI Lab, Nigeria’s government initiative, Cohere Labs — are making a different bet. They are betting that building AI that speaks the world’s most linguistically diverse continent’s languages is not only morally necessary but economically consequential. A $1.5 trillion GDP contribution estimate only materializes if AI systems can actually communicate with the people whose lives they are meant to transform.
The progress made between 2022 and 2026 — from fewer than 25 African languages supported by mainstream translation tools, to models covering 55+ languages, to community-driven datasets downloaded more than 500,000 times, to the first multilingual LLM built on African soil — represents genuine momentum.
What remains is the harder work of scale and stewardship. Extending meaningful coverage from the leading five or ten languages to the broader hundreds. Ensuring communities that contribute their language receive genuine benefit, and making sure that when AI reaches rural Kenya, peri-urban Lagos, or a village in the Ethiopian highlands, it speaks in a language those communities actually recognize as their own.
Frequently Asked Questions: African Language LLMs
Why are African languages considered “low-resource” for AI?
African languages are classified as low-resource because they lack the massive volume of high-quality, digitized, and labeled text data required to train AI models. Historically, colonial influence prioritized European languages in formal records, and many African languages rely on oral traditions, meaning they are underrepresented on the web (only 0.02% of online content).
Which AI models currently support African languages?
Several specialized and general models support African languages as of 2026. Key players include Lelapa AI’s InkubaLM (Swahili, Yoruba, Xhosa, Hausa, Zulu), Meta’s NLLB-200 (55+ languages), and Cohere’s Aya (100+ languages). Additionally, Jacaranda Health’s UlizaLlama and Princeton’s Lugha-Llama provide high-performance support for regional languages like Igbo, Luganda, and Amharic.
What is “tokenization,” and why is it a problem for African AI?
Tokenization is the process of breaking text into smaller units (tokens) for an AI to process. Most standard tokenizers are trained on English data, causing them to break African words into inefficient, nonsensical fragments. This makes models slower and more expensive to run for African languages, often leading to lower accuracy and “garbled” outputs.
Can AI help preserve endangered African languages?
Yes. Projects like NTeALan and Masakhane are using AI to digitize and standardize orthographies for languages like Bambara, Fulfulde, and Ghomala. By creating digital dictionaries and speech-to-text tools, AI helps ensure that even languages without a large web presence can transition into the digital age rather than facing “digital extinction.”
How does on-device AI benefit African users?
On-device AI, such as Tiny Aya Earth, allows language models to run locally on mobile phones without an internet connection. This is critical in Africa, where data costs are high, and cloud infrastructure is concentrated in just a few countries. It enables rural populations to access AI-driven healthcare or agricultural advice in their native tongue privately and for free.
How many African languages does GPT-5 support?
GPT-4 and similar frontier LLMs offer some coverage of high-resource African languages like Swahili, Amharic, and Hausa, but performance degrades significantly compared to English. The models were not specifically trained on African-language data and use tokenizers optimized for English. Academic benchmarks like IrokoBench and AfroBench consistently show frontier models underperforming purpose-built African-language models on tasks like named entity recognition, sentiment analysis, and QA in African languages.
Is building an AI model for African languages economically viable?
Yes — and increasingly so. The African AI market is projected to reach $16.5 billion by 2030. African-language LLMs are already being monetized in healthcare (Jacaranda Health), fintech, agriculture advisory, and government services. The on-device focus of models like Tiny Aya Earth also reduces the infrastructure cost barrier significantly. The deeper economic argument is that AI tools built in languages people actually speak will see far higher adoption rates — and with Africa’s young, growing population, that represents a massive addressable market.